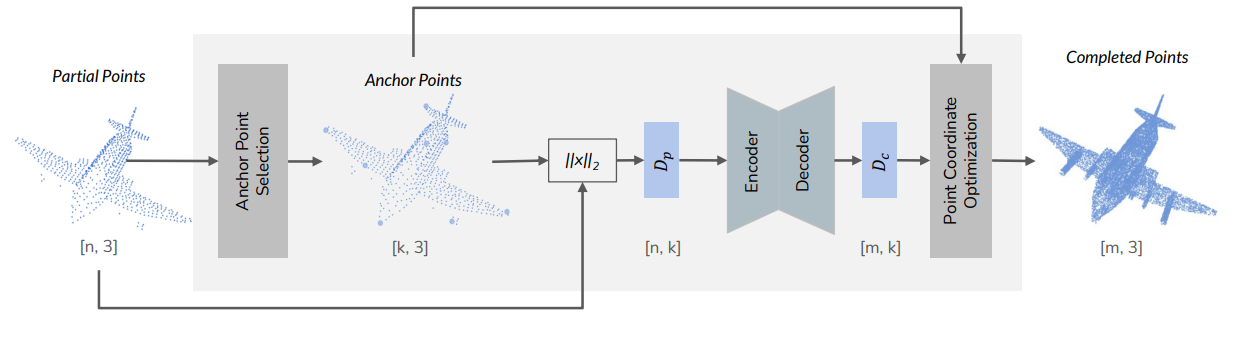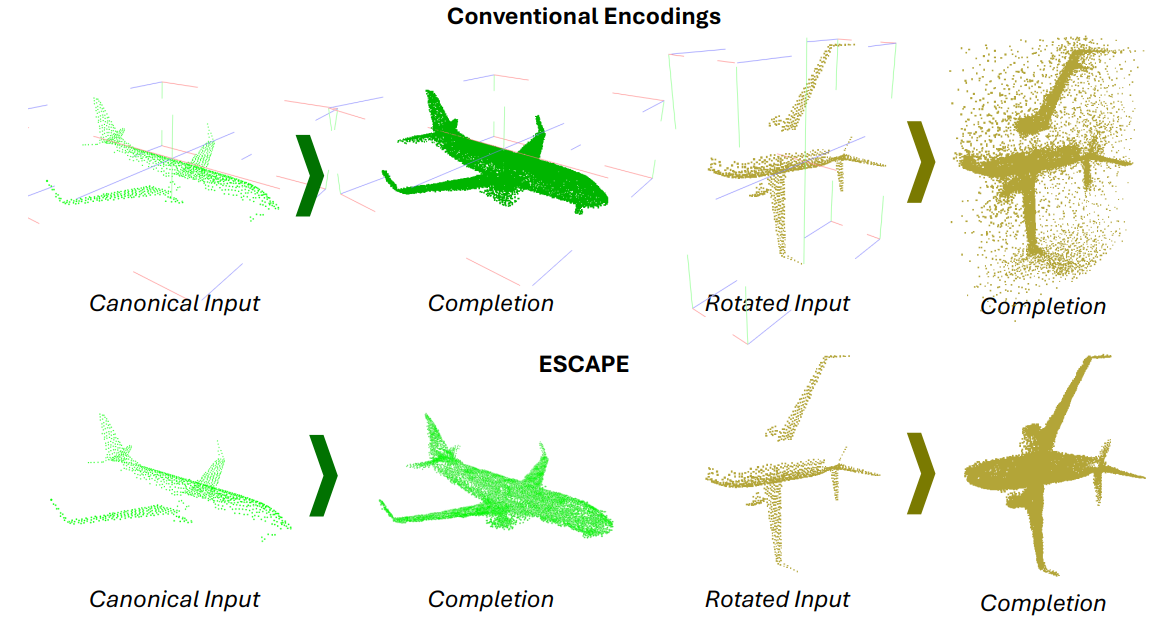
TL;DR: Encode every point by its distances to a small set of anchor points so geometry is expressed in a rotation-equivariant form; a transformer maps partial observations to completed shapes without a separate pose-estimation stage.
Preprint Paper (PDF) Code Inference notebookESCAPE (Equivariant Shape Completion via Anchor Point Encoding) targets rotation-equivariant shape completion from partial point clouds. The method selects anchor points on the shape and represents each point by its distances to all anchors, yielding a geometry-aware encoding that transforms consistently under rotations. A transformer architecture models these distance features end-to-end; an optimization step then maps predicted encodings back to completed shapes. Experiments show robust reconstructions across arbitrary rigid transforms without auxiliary pose-estimation modules, with code, pretrained models, and dataset pointers available in the project repository.
@InProceedings{Bekci_2025_CVPR,
author = {Bekci, Burak and Navab, Nassir and Tombari, Federico and Saleh, Mahdi},
title = {ESCAPE: Equivariant Shape Completion via Anchor Point Encoding},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2025},
pages = {6480--6489}
}